Speed Up File Compression with Pigz: Parallel GZip Implementation

Search for a command to run...
No comments yet. Be the first to comment.
Riding the Coin Pusher of Life

How to Write Tasks for Humans and Machines
The pursuit of Artificial General Intelligence (AGI) — a concept I learned about this week — is often framed as a climb toward a distant mountain peak. We define it broadly, as an AI that matches or exceeds the sum total of human capability—the abili...

Turn Your Git Repository into an SQL Database with gitstatdb

Hacktoberfest 2025 just finished — and guess what? They brought back the swag!After last year’s digital-only celebration, seeing the return of t-shirts and tree-planting rewards brought a wave of nostalgia and motivation 😊 For some reason, I didn’t ...

devpassion Tech Insights, Open Source & Personal Growth
26 posts
I wear many hats in my professional life - developer, system administrator, and even a teacher at times. You could say I have a mixed bag of skills and experiences, both good and bad. One thing I absolutely love is writing, so you'll find some of my content floating around the web, along with a ton of code.
I learned about pigz today. While reviewing the processes in one of my Linux servers I saw this process eating up the CPU resources and immediately thought it was some cryptocurrency mining hack. After some investigation, I found a VERY nice tool!
From the manual page:
Pigz compresses using threads to make use of multiple processors and cores. The input is broken up into 128 KB chunks with each compressed in parallel. The individual check value for each chunk is also calculated in parallel.
So a gzip that uses all the processors in the server to do its work faster. Let's give that a try.
I look around the server and find a 14Gb SQL dump file of one of our databases. It's a perfect file for a compression test. So I compress and uncompress it with pigz and gzip.
time pigz cbcrm_pre_update_30052024.sql
time unpigz cbcrm_pre_update_30052024.sql.gz
time gzip cbcrm_pre_update_30052024.sql
time gunzip cbcrm_pre_update_30052024.sql.gz
The results:
| Command | Real | User | System |
| pigz | 1m54.518s | 1m18.354s | 0m13.380s |
| unpigz | 1m38.363s | 0m49.843s | 0m20.917s |
| gzip | 4m6.779s | 3m53.000s | 0m8.151s |
| gunzip | 1m37.684s | 0m59.503s | 0m7.100s |
The time for compression has a significant difference, while the uncompression is almost similar, I suppose due to the complexities of creating meaningful chunks of compressed data and the internals of the gzip format.
The htop output shows a clear difference in server resource usage:
These first two images are two different moments of the pigz execution:
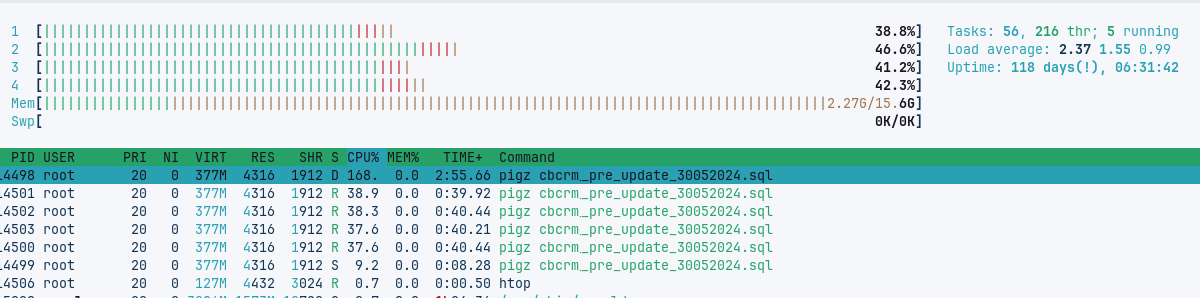
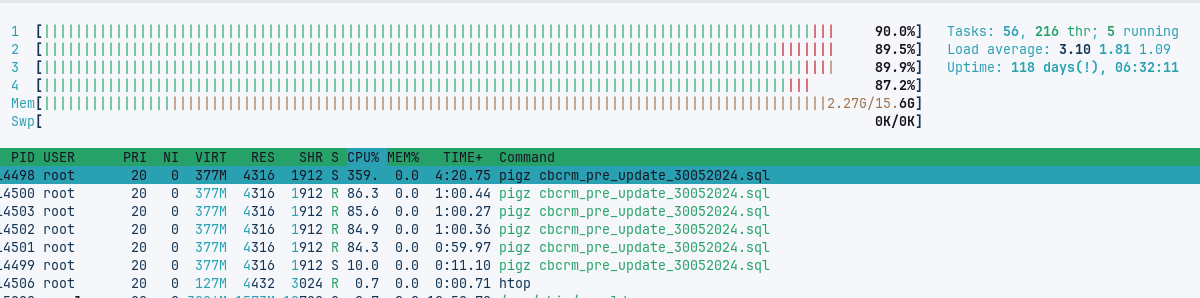
where we clearly see all CPUs working together. The next two images are for the gzip execution.
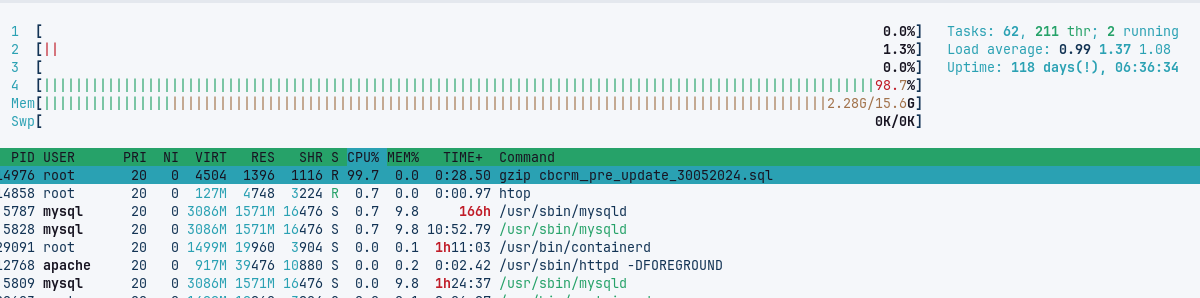
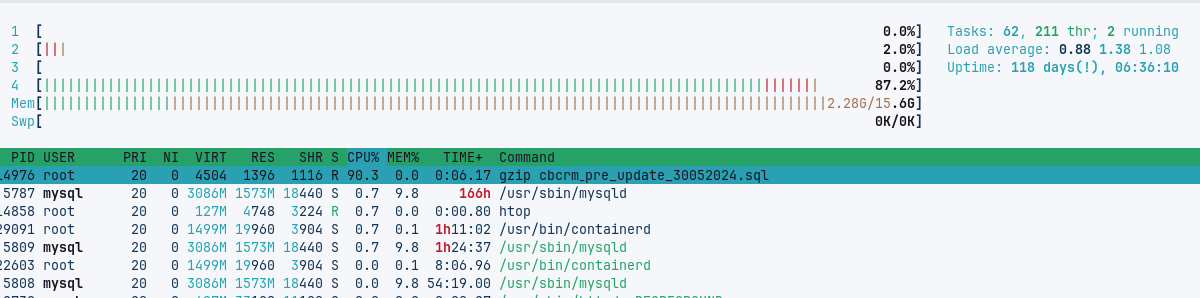
where we see the lack of parallel computing. The unzip executions look similar.
In the Altlantic article referenced below and in the manual you will find some useful execution options and combinations.
A very practical use of programming and server knowledge! Kudos to the pigz team.